

INTRODUCTION
Data privacy laws complicate the ability of companies to manage information by: (1) compelling their destruction before fulfilling business or operational needs; and (2) limiting how information can be shared or transferred. This article discusses anonymization techniques and options to deal with compelled destruction requirements for companies collecting and storing personal information for valid business reasons. It also briefly explores arguments about sharing, transferring, and even publishing personal data that has been anonymized.
Laws
To explain the options anonymization can provide, it’s useful to first set the legal landscape by discussing data privacy laws and definitions. A type of privacy law that often causes compliance headaches for many companies is compelled destruction requirements, which specify a fixed or event-driven amount of time in which personal data must be destroyed. The Netherlands “Exemption Data Protection Act” contains many examples of compelled destruction requirements. One example, article (8)(5) requires that “payroll data be deleted no later than two years after the employment.”[1] This demonstrates how little room for interpretation compelled destruction requirements allow. The problem is that most companies need to keep payroll records for longer than 2 years after employment ends for operational reasons, such as defending against wage and discrimination claims and reviewing an employee’s payment history to guide requests or analysis for wage increases.
What constitutes personal information is not usually as clear as the Netherlands example. It will be defined by each law, and is not usually limited to just sensitive information, such as social security numbers, or financial and health information. Most laws take a more ubiquitous approach, for example the UK’s Data Protection Act defines personal data as “…data that relates to a living individual who can be identified from those data or from those data and other information which is in the possession of, or is likely to come into the possession of, the data controller and includes any expression of opinion about the individual…”[2] Data controllers are defined broadly, to include anyone “obtaining, recording or holding the [personal] information or data.”[3] Information that, when combined with other information that is or could likely become available, identifies an individual, would meet the above definition of personal data.[4]
Anonymization Options:
The UK Information Commissioners Office (ICO)[5] defines Anonymization as “the process of turning data into a form which does not identify individuals and where identification is not likely to take place.[6]” There are several anonymization methods which will be explained in the table below, but all generally seek to remove identifiers by removing, masking, or disguising personal information. Used correctly, the ICO provides that “anonymization can allow us to make information derived from personal data available in a form that is rich and usable, whilst protecting individual data subjects.”[7]
UK’s Information Commissioners Office developed an Anonymization Code in the context of sharing data that otherwise would be restricted by privacy concerns, but it’s also useful in exploring options for companies retaining personal information. The code states that if techniques are correctly used, it will allow many types of anonymized data to be shared publically and privately in compliance with the UK Data Protection Act and other Privacy Regulations.[8] The threshold used is the likelihood of identification at the time of the data share and the standard is not that re-identification is impossible, but that given the data that is currently out and likely to come out in the near future, that re-identification is unlikely.[9]
Which anonymization option to use depends on the situation and the goals of the anonymization project.[10] The table below lists many of the options for anonymization and is categorized by the basic principle involved in the anonymization. It also lists variations, and general as well as company-specific uses, including its usefulness in dealing with personal data.
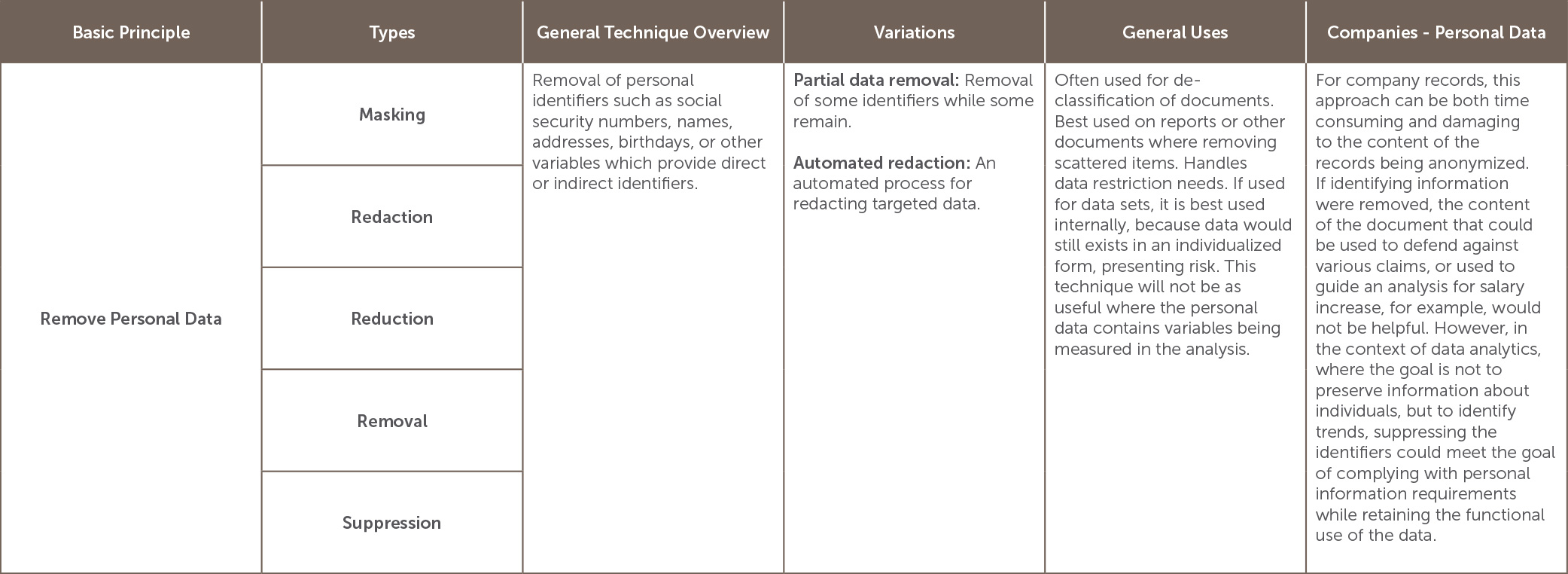

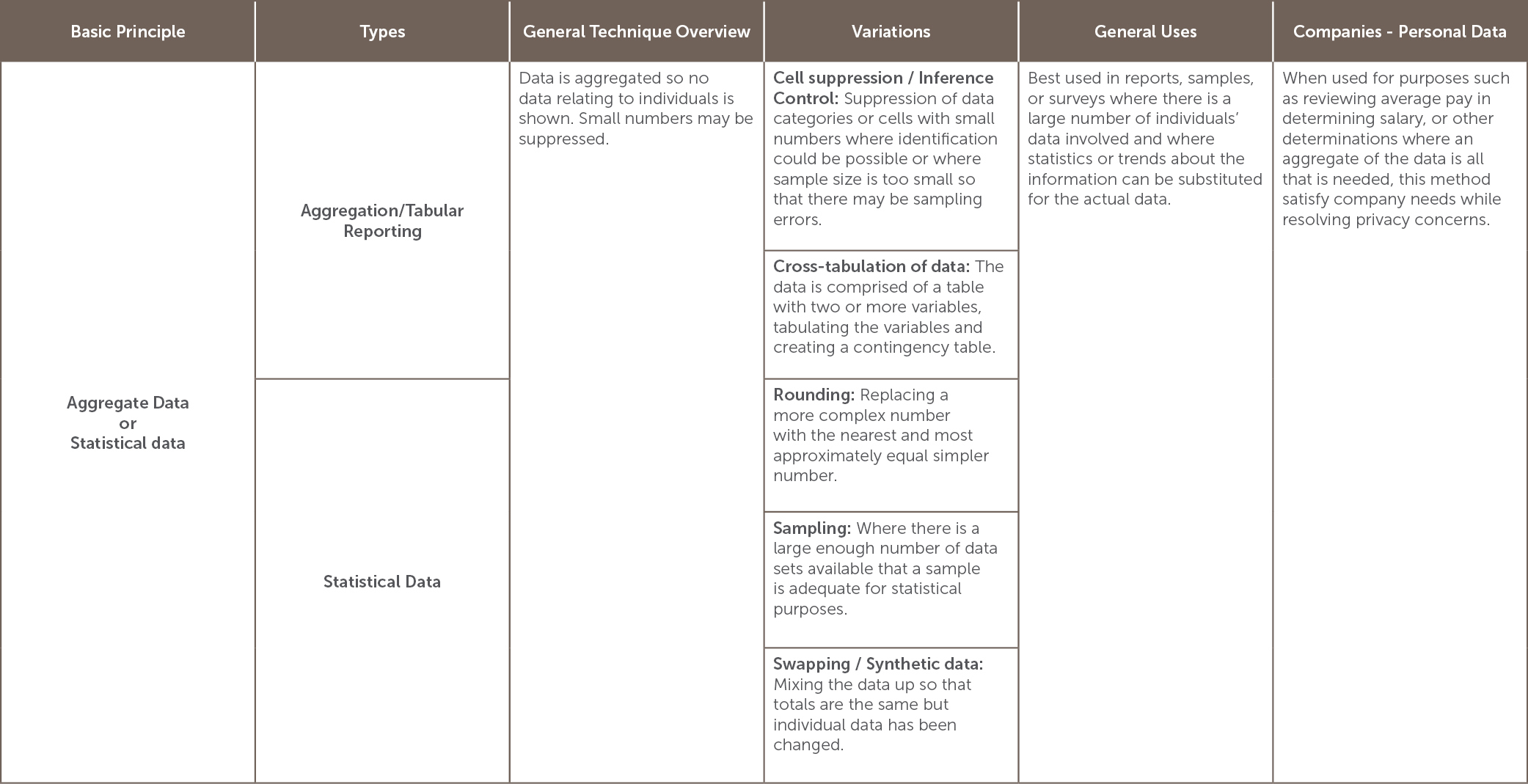
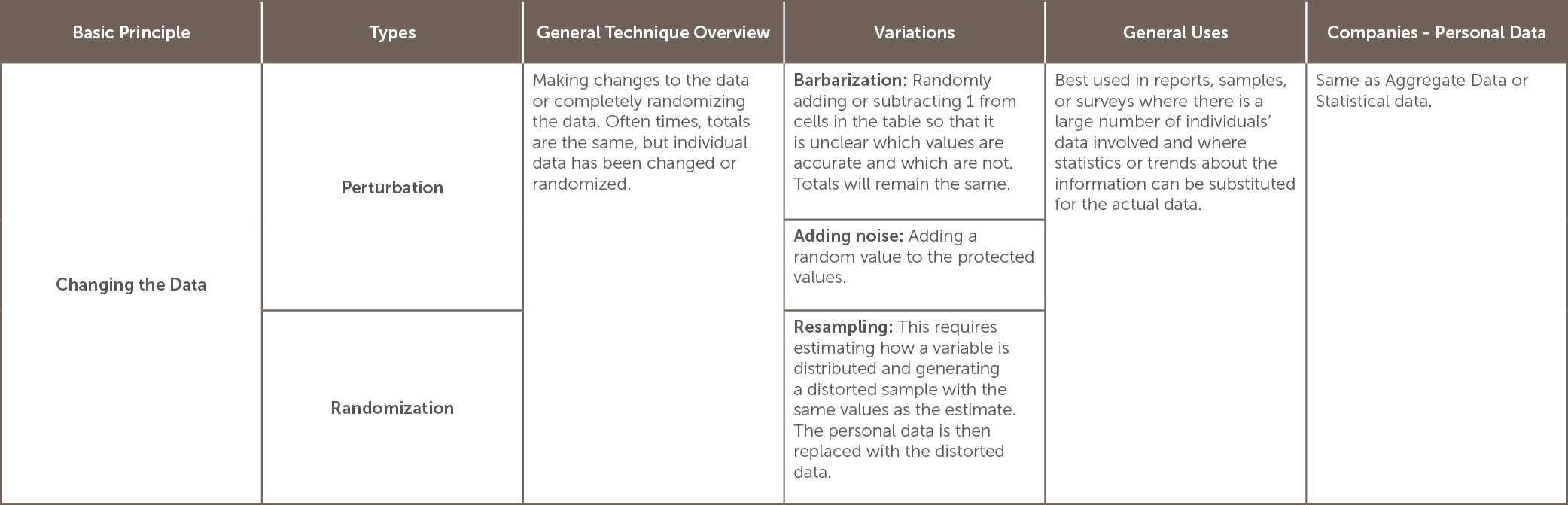

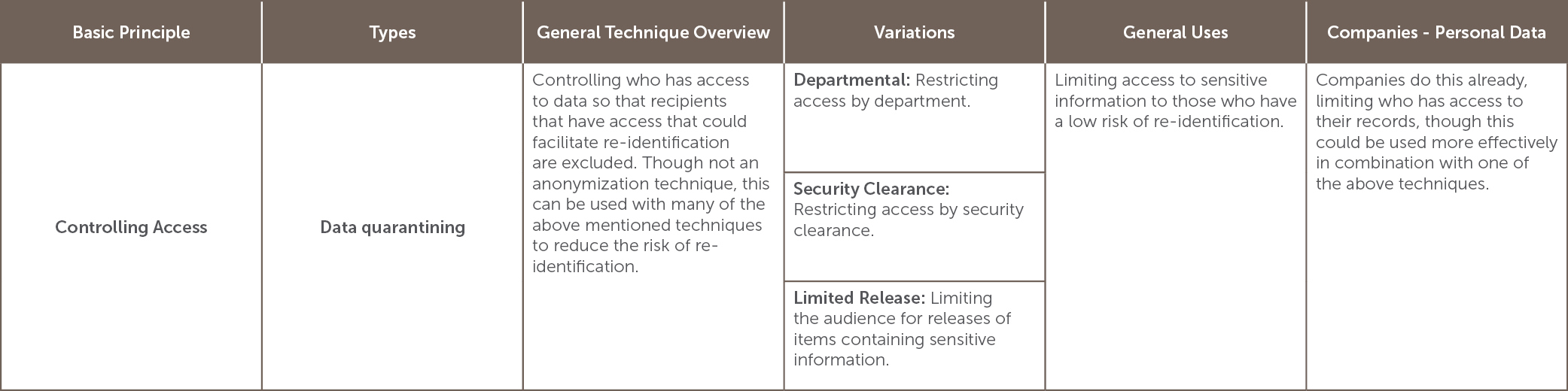
[11]
USING ANONYMIZATION FOR COMPLIANCE
Encryption, as outlined above, is a powerful tool for companies looking to comply with compelled destruction requirements. Encrypted data is anonymized data that has a potential to be re-identified through the use of a key. By definition, anonymized data falls outside the scope of the compelled destruction requirements in many personal data laws. Some laws go so far as to state so expressly, like the UK Protection Directive of 1995, which provides that its regulations on data protection do not apply to “data rendered anonymous in such a way that the data subject is no longer identifiable.”[12]
The major key to the success of anonymization is anticipating and preventing re-identification, as the parties of some high profile examples of failed attempts can confirm. For example, when AOL released search queries from its users over a three-month span, it replaced user IDs with unique numbers, but used a deterministic modification method, meaning that every search conducted by the same user had the same unique number.[13] The content of the searches themselves, like searches based on dating habits, ailments, dog training, and for real estate, were enough for reporters from the New York Times to identify one user.[14] Because the searches themselves contained personal information that could be analyzed to re-identify, they should have been further anonymized to prevent re-identification, even if that meant some loss of valuable data. In another example, Netflix released a dataset of user movie ratings as part of a competition to improve its recommendations analytics method.[15] Researchers were able to use that data, along with publically available ratings information from IMDB, to identify some users.[16] In releasing the data, Netflix failed to identify public information that could be used in conjunction with the data to re-identify.
One issue increasing the likelihood of re-identification is that releases of anonymized data draw the attention of computer scientists that see re-identification as a resume-building activity. [17] This incentivizes re-identification at the cost of the individuals whose data is then released.[18] Without these efforts, it may be unlikely that re-identification would occur, but with the increased attention, a higher level of sophistication is necessary to prevent against re-identification. Going back to the guidance provided by the UK’s Information Commissioners Office, the level of sophistication that previous re-identification efforts exhibited should be taken as a warning to companies looking to release anonymized data. Increased planning and scrutiny of data will be necessary before future release occurs, and the threshold that re-identification will be unlikely has become more complicated and difficult to meet.
Given this threshold, there are some that question the feasibility of anonymization in publically releasing de-identified data in general.[19] They question whether it is ever really unlikely that re-identification will occur with developing technology and capabilities [20] Paul Ohm, an associate professor at University of Colorado Law School, goes so far as to state that “data can be either useful or perfectly anonymous but never both.”[21] The counter to this argument is that it’s a sensationalist theory based on assumptions, and that examples of failures to adequately anonymize do not condemn the practice, but instead provide learning opportunities to improve. [22]
CONCLUSION
Whether heightened scrutiny and better anonymization techniques will lead to a lower chance of re-identification when data is released publically is a debate that only the success or failure of more thorough future anonymization attempts will decide. However, anonymizing data and keeping it internal, or limiting the audience that has access, is a step in the right direction for companies seeking compliance with privacy laws. The risk of re-identification discussed in the high profile Netflix or AOL cases would have been highly unlikely if the anonymized data was kept private or released to a controlled audience. A controlled release, or keeping the data internal, provides the protections that data privacy laws and compelled destruction requirements mandate while letting companies keep information for a reasonable time based on their operating and liability needs.
Disclaimer: The purpose of this post is to provide general education on Information Governance topics. The statements are informational only and do not constitute legal advice. If you have specific questions regarding the application of the law to your business activities, you should seek the advice of your legal counsel.
[1] Netherlands Exemption Data Protection Act 2013 (8)(5), http://wetten.overheid.nl/BWBR0012461/geldigheidsdatum_02-05-2013
[2] United Kingdom Data Protection Act 1998 (1)(1), (Reprinted Incorporating Corrections 2005). http://www.legislation.gov.uk/ukpga/1998/29/pdfs/ukpga_19980029_en.pdf
[3] Id.
[4] See UK Information Commissioners Office “Anonymization: managing data protection risk code of practice” Chapter 2 “Anonymization and personal data” https://ico.org.uk/media/for-organisations/documents/1061/anonymization-code.pdf
[5] The UK Information Commissioners Office is an Authority created to “uphold information rights in the public interest, promoting openness by public bodies and data privacy for individuals.” They are tasked with enforcing the UK Data Protection Act 1998 and created the “Anonymization: managing data protection risk code of practice.” https://ico.org.uk/about-the-ico/
[6] UK Information Commissioners Office (ICO) Anonymization webpage. https://ico.org.uk/for-organisations/guide-to-data-protection/anonymization/
[7] UK Information Commissioners Office “The Guide to Data Protection” Information Commissioner’s foreword “Retaining personal data (Principle 5)” https://ico.org.uk/for-organisations/guide-to-data-protection/
[8] Id. at Section “Retaining personal data (Principle 5)”
[9] Id. at Section 1 “About this code.”
[10] See UK Information Commissioners Office “Anonymization: managing data protection risk code of practice” Annex 3 for “Practical examples of some anonymization techniques” https://ico.org.uk/media/for-organisations/documents/1061/anonymization-code.pdf
[11] Summarized from Id.
[12] Id. at “Information Commissioner’s foreword”
[13] A Face Is Exposed for AOL Searcher No. 4417749 http://www.nytimes.com/2006/08/09/technology/09aol.html?pagewanted=all&_r=0
[14] Id.
[xv] Netflix Prize Competition. http://www.netflixprize.com/
[15] Researchers reverse Netflix anonymization http://www.securityfocus.com/news/11497
[16] “Anonymized” data really isn’t—and here’s why not. http://arstechnica.com/tech-policy/2009/09/08/your-secrets-live-online-in-databases-of-ruin/ discussed how Latanya Sweeney and other computer scientists take re-identification as a challenge.
[18] Id.
[19] Sticky data: Why even ‘anonymized’ information can still identify you. http://www.theglobeandmail.com/technology/digital-culture/sticky-data-why-even-anonymized-information-can-still-identify-you/article19918717/
[20] The authors state that “there is no evidence that de-identification works either in theory or in practice and attempts to quantify its efficacy are unscientific and promote a false sense of security by assuming unrealistic, artificially constrained models of what an adversary might do.[xx]” No silver bullet: De-identification still doesn’t work; Arvind Narayanan & Edward W. Felten. July 9, 2014. http://randomwalker.info/publications/no-silver-bullet-de-identification.pdf
[21] University of Colorado Law School associate professor Paul Ohm: Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization. August 13, 2009. UCLA Law Review, Vol. 57, p. 1701, 2010. U of Colorado Law Legal Studies Research Paper No. 9-12
[22] Big Data and Innovation, Setting the Record Straight: De-identification Does Work. Ann Cavoukian, Ph.D. Information and Privacy Commissioner Ontario, Canada. Daniel Castro, Senior Analyst, Information Technology and Innovation foundation. June 16, 2014. http://www2.itif.org/2014-big-data-deidentification.pdf

Author: Rick Surber, CRM, IGP
Senior Analyst / Licensed Attorney