

If you’ve been in the business of Information Governance for very long you have likely seen many debates or discussions about the best way to do retention scheduling. Common considerations include the ideal size, big buckets vs. small, departmental vs. functional, knowing and applying the appropriate laws, etc. After much time and toil, you may even have created the perfect records retention schedule. You received sign-offs, trained key users, and published it. Congratulations!
One year later, during your planned review, you find few, if any, are actually using it. How could that be? It has the perfect number of categories, flows logically, is backed up with current legal research, has the blessing of upper management, and training was thorough.
The problem is likely not with the schedule itself, or with training, but a matter of process. Records retention is one more step in an already complex list of processes. The legal expert cares about creating a good contract, not how long it’s is retained. The salesperson is all about closing the deal, not where to keep the proposal. To make a retention schedule effective, we have to make it easy. Don’t attempt to push water uphill.
Getting a records retention schedule into your everyday business processes is also known as operationalizing it. Blending it into your day-to-day workflow is the goal. The idea is simple in concept, but there are many hurdles to overcome in making it real. You must consider the types of records you’re dealing with, how and where they’re stored, and who has access to them. Also, whether their retention is event-based, whether or not the information is maintained consistently, and the scope of technology and expertise you will be able to leverage.
Before starting down this path you first need to answer a key question. “How much control do you need over the retention and disposition of records across the organization?” If your main function is to develop policies and disseminate the information, but not to validate or enforce, then this discussion is not for you. If you are responsible for ensuring records are maintained according to the policy, then by all means read on.
The second key question is: “How are you managing your retention schedule?” If it’s document-based, such as with spreadsheets or word processing documents, this process is going to be very manual. You will be manually updating retention policies in each system (assuming those systems have retention capabilities). And, you will rely on whatever tools are available within those systems to calculate retention dates and process dispositions. If you only have 2 or 3 major systems this may be feasible, but if you have 200 or 2000 systems, it will be nearly impossible.
A corollary question is: “Do you have the means to calculate retention dates once the policies have been applied to records in your repositories?” Without this capability, you may only complete a half-step toward operationalizing – assigning the policy but not being able to do much with it.
Start with a Data Inventory
In the process of developing a retention schedule, you likely conducted a data inventory. This may have come through interviews with stakeholders, a review of your IT department’s backup procedures, file analysis software, or some combination of all three. If you haven’t gone through this step, I highly recommend it. From your data inventory (a.k.a. data map) you should be able to know which major systems hold key records, who manages those systems, and which ones are used most.
You may also have mapped the inventory to your retention schedule, at least by listing the system of record for each retention category. This will let you know which retention policies apply to which repositories. This exercise can also uncover which systems tend to hold more transitory information versus long-term records.
If you analyze your data map you will likely find that the 80/20 rule holds true: 80% of your records are probably maintained in 20% of your major repositories. In some cases, it may even be 90/10. For example, it is quite common to have most records of concern maintained in shared drives and/or SharePoint.
Understand the Retention Capabilities
Armed with the top 20% of systems that contain most of your records it’s time to dig into the details of those repositories. You need to determine their actual capabilities for managing retention and disposition. For this, you will need a subject-matter expert (SME) for each of the systems you want to evaluate. You already know from your data inventory what kinds of records are stored, and perhaps in what format. You will now need to find out the following about each of the repositories in question:
- Does the system have internal retention policies and disposition processes?
- If so, is it possible to update those policies from another system, such as through an API (Application Programming Interface)?
- Is it a good place to keep records long term, if necessary?
- If no to any of the above, then is the metadata of the records accessible through an API?
- If no again, then how easy is it to move or export records from the system?
After answering the questions above you should be able to categorize each system into one of the following quadrants. The upper-right quadrant is the most automated scenario and lower-left the most manual. Whether automated or manual, the main goal is to have a consistent process that is easy to maintain. All of the scenarios are predicated on the assumption that you have a tool for managing your retention schedule, and that you have a way to calculate retention dates for those systems that don’t have such capability.
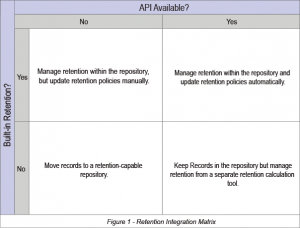
Each quadrant deserves a bit of explanation.
Lower-Left – As mentioned above, this represents the most manual scenario. The repository in question has no built-in retention capabilities and no API for integrating with an external calculation tool. Shared drives are a good example of this type of system. You must either move the important records out to a separate system or find a purpose-built tool that synchronizes with the documents to calculate retention dates and process dispositions. It would be easy to label this as the worst-case scenario, but in reality, it only means that it is entirely manual. In many cases, a manual process can be the best and most efficient solution if there are few systems to manage. The cost of automation may outweigh the long-term efficiencies gained.
Lower-Right – In this scenario, you can keep the records in the repository. But, you will need a separate retention calculation tool to pull metadata via the API and use it to calculate retention dates. The repository has no native retention calculation tools of its own. This is often the case with imaging systems, where the primary function is digitizing documents, not records management.
The retention tool should at least be able to calculate retention dates, but may also be able to execute destructions in the target system. Some systems may be able to auto-classify the data based on content. More likely, however, the date calculations will be based on rules applied to the metadata values. For example, all documents from the Legal department with a document type of Commercial Contract will be assigned to a record series geared to such contracts.
Upper-Left – Here again you can keep records in the repository, but with no API available you will have to update retention policies manually each time your RRS is updated. If your schedule is updated infrequently, this may not be a problem. Document management systems often fall into this category.
Upper-Right – This is considered the best-case scenario, because you can keep the records in the native repository, but will depend on the overall cost/benefit analysis. You can utilize built-in retention scheduling options, and keep the retention policies up-to-date through APIs that are connected to your retention scheduling tool. Each time you update the RRS, the API will ensure those updated policies make it into the repository so they can be applied to records.
Some of these models can have hybrid options. For example, a system may not have an API for automatically importing retention policies, but you may be able to manually import the schedule from a flat file, such as a spreadsheet or CSV (Comma Separated Values) text file.
Publisher/Subscriber Model
There is another concept that would fit into the Upper-right quadrant, but which requires some additional explanation. It involves a concept called middleware, and is reserved for large enterprises where there might be hundreds or even thousands of applications for which retention needs to be managed.
Even with the availability of APIs, you can imagine that the maintenance of 2,000 or 3,000 applications all talking to one another through electronic connections could quickly become unmanageable chaos. APIs may facilitate automation, but they are not auto-magic.
This is where middleware comes into play. As the name implies, it stands between applications to share common information. As an example, let’s assume you have 20 different systems that all use customer information. Rather than keeping 20 different versions of that data, you would want to synchronize them so all use a common source of truth. So, you would synchronize one system with 19 others, creating 19 distinct connections. But, if each of those 20 systems held some common piece of information needed by all the rest then you would need 190 distinct connections. In the unlikely scenario that you have 2,000 systems that all need to share data with each of the others, then it grows to 1,999,000 distinct connections!
Having a publisher/subscriber middleware platform greatly simplifies that mess by allowing any system that is the source of truth to be a Publisher and any other system that needs the data to be a Subscriber to that topic. Hence one connection for the publisher, and one for each subscriber. That could still add up to a number of connections, but the connections are simpler because they connect to a common hub. In our scenario, that means one publisher of the retention schedule and multiple subscribers who can pull in the schedule automatically.
About APIs
API is one of those acronyms that you may hear often but not fully understand. Let’s take a moment to ensure the meaning is clear. As mentioned earlier, API stands for Application Programming Interface. You can think of it as a window into a black box. It is a set of protocols, or pre-defined instructions, for how to get information into and out of the black box without having to know all of the complicated structures inside the box. SharePoint is a great example. It would be unreasonable to attempt to dissect such a beast to figure out how to get data into or out of it. But the developers of SharePoint have created methods that can be called by other programs to do specific tasks. For example, if Zasio’s Versatile Retention product wants to export retention schedule information to SharePoint our developers can make a series of calls to the SharePoint API library. It might start with going to an internet URL and checking for the existence of a SharePoint server, followed by another URL that expects us to send user credentials to login to that server. Another call might request access to Information Management Policies, and yet another would create new management policies. Each API has a library of such commands that developers can utilize, each with published parameters regarding what information is expected when making the call, and what will be returned when the call is completed – all without having to know the internal structure or mechanisms.
Deployment
Once you have determined strategies for the major systems to which you need to apply retention policies it’s time to put them into place.
Start with that top 20%, or even just one major system, to begin with, depending on what resources you have available. Work with the SME of the given system(s) based on the type of integration determined by the matrix above. You will also likely need to involve IT and possibly a project manager. The checklist below can be used as a rough guide for how to proceed, although it can vary widely depending on the scope of the project, and the type of integration being attempted.
- Create a test environment that includes both the target system you need to update and the source system containing retention policies.
- Develop a proof-of-concept involving one or two retention policies from the source system that you want to update in the target system.
- Determine the method you will use to get the data from the retention management system to each repository. If you’re shooting for an automated process then you will need a way to manually trigger that automation to run through several iterations. It may involve a system specifically designed for creating business process management (BPM) workflow. If the data transfer is entirely manual, you still need to define exactly what fields will be used, what tools will be involved, and the step-by-step instructions of how it gets from one place to the other, so anyone can replicate it.
- Execute the test transfer with your selected retention policies using the step-by-step instructions.
- Validate that the data is transferring and updating correctly. Adjust as necessary.
- Enhance the proof of concept to have the process automatically triggered, either by a timed schedule or based on the completion of some other task, like updating the retention schedule. This is true even for manual processes – something must trigger a user to take the necessary action, such as a reminder email that is delivered automatically.
- Test some more, with different scenarios, then test again.
- Plan the transition from test into production, being sure to communicate with all down-stream parties who will be affected by the change.
- Execute the plan, monitor, and adjust as needed.
- Target the next system and repeat.
Automatic Disposition
If the integration process includes the ability to automatically dispose of records then your compliance work will be easier, but you will have to do more on the front end to ensure it’s only destroying records that are supposed to be destroyed. You will likely need to involve internal legal counsel to sign-off on the automated process, and only after thorough testing.
Some of the risk can be mitigated by having the equivalent of a recycle bin. That means you have a period such as 30 days in which to reverse the disposition process. You might also build a final approval step into the process requiring a person to push the final button. In any case, you will want to ensure the process has audit trails that will allow you to see what has been destroyed, and by what criteria.
Event-based Retention Rules
Retention policies based on dates not known at the time a record is created pose a frequent hindrance to operationalizing a retention schedule. Consider a contract for maintenance services, for example. Obviously, you will keep documents related to that contract for as long as it is active, at least, but no one knows how many years the contract might be renewed. To make matters worse, once the contract is terminated there is usually no mechanism in place to update whatever system is doing the retention calculation to act on that event. Employment records are another good example because they are often based on the duration of employment plus some number of years. You don’t know if an employee will be with the company for 2 years or 20.
There are generally two strategies for dealing with event-based retention.
- Extend the retention period for the category to the longest possible duration of any event-plus date range. For example, if policy documents are normally kept for a period of Superseded + 1 year, and policies are reviewed annually then you could safely change the retention period to Creation Date + 2 years. Or, make it 3 years to be on the safe side.
- Utilize workflow management to ensure that updates to event trigger dates are pushed out to the system that calculates retention dates. For example, within the legal department make sure that when a matter is closed that the close date is sent to the records management system so it can calculate the actual disposition date.
Retention Holds
Any automated retention and disposition process must also have the ability to easily freeze records. This ensures the disposition process can be halted for records subject to litigation or audit. It’s like an emergency stop button on an assembly line.
Summary
If the automatic application of retention policies seems like fantasy land, think about what the information governance landscape will be like in 10 years if you don’t start down this path now. The growth of information and applications is only going to increase. If it seems unmanageable now it will be exponentially harder a few years from now.
Ideally, once you have established some successful integrations you will want to build this process into your new application onboarding procedures so that information generated by the new system won’t get out of control like so many others. Make it part of the onboarding checklist: “Does this system have retention capabilities?” If not, “How will retention be managed in this repository?”. If you can’t answer those questions, perhaps it’s not the right system for you. And, before implementation can be considered complete, ensure the retention and disposition processes have been successfully tested.
By making retention integrations a core part of your business processes, you can enjoy the confidence that comes from staying one step ahead of the chaos that is sure to come without it. In addition, one step ahead of auditors, data protection, dark data, and redundant/obsolete/trivial data (ROT).